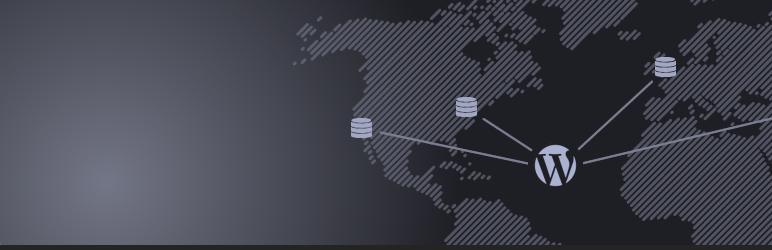
Descripción
HyperDB is a very advanced database class that replaces a few of the WordPress built-in database functions. The main differences are:
* HyperDB can be connect to an arbitrary number of database servers,
* HyperDB inspects each query to determine the appropriate database.
It supports:
- Read and write servers (replication)
- Configurable priority for reading and writing
- Local and remote datacenters
- Private and public networks
- Different tables on different databases/hosts
- Smart post-write master reads
- Failover for downed host
- Advanced statistics for profiling
- WordPress Multisite
It is based on the code currently used in production on WordPress.com with many MySQL servers spanning multiple datacenters.
Instalación
Nothing goes in the plugins directory.
-
Enter a configuration in
db-config.php. -
Deploy
db-config.phpin the directory that holdswp-config.php. This may be the WordPress root or one level above. It may also be anywhere else the web server can see it; in this case, defineDB_CONFIG_FILEinwp-config.php. -
Deploy
db.phpto the/wp-content/directory. Simply placing this file activates it. To deactivate it, move it from that location or move the config file.
Any value of WP_USE_MULTIPLE_DB will be ignored by HyperDB.
FAQ
-
What can I do with HyperDB that I can’t do with WPDB?
-
WordPress.com, the most complex HyperDB installation, manages millions of tables spanning thousands of databases. Dynamic configuration logic allows HyperDB to compute the location of tables by querying a central database. Custom scripts constantly balance database server resources by migrating tables and updating their locations in the central database.
Stretch your imagination. You could create a dynamic configuration using persistent caching to gather intelligence about the state of the network. The only constant is the name of the configuration file. The rest, as they say, is PHP.
-
How does HyperDB support replication?
-
HyperDB does not provide replication services. That is done by configuring MySQL servers for replication. HyperDB can then be configured to use these servers appropriately, e.g. by connecting to master servers to perform write queries.
-
How does HyperDB support load balancing?
-
HyperDB randomly selects database connections from priority groups that you configure. The most advantageous connections are tried first. Thus you can optimize your configuration for network topology, hardware capability, or any other scheme you invent.
-
How does HyperDB support failover?
-
Failover describes how HyperDB deals with connection failures. When HyperDB fails to connect to one database, it tries to connect to another database that holds the same data. If replication hasn’t been set up, HyperDB tries reconnecting a few times before giving up.
-
How does HyperDB support partitioning?
-
HyperDB allows tables to be placed in arbitrary databases. It can use callbacks you write to compute the appropriate database for a given query. Thus you can partition your site’s data according to your own scheme and configure HyperDB accordingly.
-
Is there any advantage to using HyperDB with just one database server?
-
None that has been measured. HyperDB does at least try again before giving up connecting, so it might help in cases where the web server is momentarily unable to connect to the database server.
One way HyperDB differs from WPDB is that HyperDB does not attempt to connect to a database until a query is made. Thus a site with sufficiently aggressive persistent caching could remain read-only accessible despite the database becoming unreachable.
-
What if all database servers for a dataset go down?
-
Since HyperDB attempts a connection only when a query is made, your WordPress installation will not kill the site with a database error, but will let the code decide what to do next on an unsuccessful query. If you want to do something different, like setting a custom error page or kill the site, you need to define the ‘db_connection_error’ callback in your db-config.php.
Reseñas
Colaboradores y desarrolladores
«HyperDB» es un software de código abierto. Las siguientes personas han colaborado con este plugin.
ColaboradoresTraduce «HyperDB» a tu idioma.
¿Interesado en el desarrollo?
Revisa el código , echa un vistazo al repositorio SVN o suscríbete al registro de desarrollo por RSS.
Registro de cambios
1.9
- Restore the behavior where we retry failed connection attempts to masters;
- Unbreak the logic for marking servers as down – in r2625068 the key for marking server as down was mistakenly changed to «server_readonly_$host$port» instead of «server_state_$host$port»
- If all masters are marked as read-only, ignore the read-only flag and still try to connect; otherwise we might end up incorrectly breaking the master connections for 2 minutes (APCu cache time) if we had temporarily set read-only on them;
- Fix a bug where having $dbhname in the server state keys can delay marking server as down or read_only by doing it once for all possible datasets and operations instead of once for the host+port;
- Fix a bug where we could mark server as read-only even though the ER_OPTION_PREVENTS_STATEMENT error was returned for a different reason; now we match to make sure we actually have ‘read-only’ in the returned error;
- Fix a bug where the correct tracking of the unique read-only servers or lagged slaves might fail if we have duplicate servers for the same dataset;
- Fix a bug where we would not mark masters as read-only in HyperDB if they were set read-only on the server side after we already opened a connection;
- Fix a bug where we might stop respecting the minimum configured amount of retries per dataset;
- Revert the persistent unused_servers logic which was added in HyperDB 1.8 because: it can cause connection failures when the available servers are exhausted, we might use servers with wrong priorities, and not see newly added servers to HyperDB. Some examples of conditions which would trigger these behaviors include: server-side disconnects on timeout; when we manually disconnect open connections in long-running scripts; when we switch between different datasets on the same remote MySQL server; we’ve gone over the configured max_connections and started disconnecting existing connections to accomodate new ones;
- Make sure the read_only and the downed logic still works in environments which don’t have APCu or APCu is badly fragmented by adding local caching
- Correct the dbh property type
- PHP 8.0 compatibility for call_user_func_array() and db_connections attribute
1.8
- Support for fallback master connections
- Add support for marking servers read-only
- Fix the issue when
do_action()is not available - Use APCu to cache the results of server responsiveness
- Add support for the
utf8mb4server capability
1.7
- Add support for information_schema and transactions
- Requires WordPress 4.2 for wpdb::get_table_from_query()
1.6
- Add support for MYSQL_CLIENT_FLAGS which was added to wpdb in [21609]
- Fix PHP 7.3 Notice
1.5
- Fix WordPress 4.8.3 SQLi vulnerability
- Add action for SQL logging
- Never db_connect for SELECT FOUND_ROWS()
- Better cleanup when disconnecing db connections
1.4
- Additional logging for HyperDB failures and do not save «null» queries.
1.3
- Improved failed query tracking
1.2
- PHP7 compatability
- MySQLi support
- Allow utf8mb4 character set
1.1
- Extended callbacks functionality
- Added connection error callback
- Added replication lag detection support
1.0
- Removed support for WPMU and BackPress.
- New class with inheritance: hyperdb extends wpdb.
- New instantiation scheme: $wpdb = new hyperdb(); then include config. No more $db_* globals.
- New configuration file name (db-config.php) and logic for locating it. (ABSPATH, dirname(ABSPATH), or pre-defined)
- Added fallback to wpdb in case database config not found.
- Renamed servers to databases in config in an attempt to reduce ambiguity.
- Added config interface functions to hyperdb: add_database, add_table, add_callback.
- Refactored db_server array to simplify finding a server.
- Removed native support for datacenters and partitions. The same effects are accomplished by read/write parameters and dataset names.
- Removed preg pattern support from $db_tables. Use callbacks instead.
- Removed delay between connection retries and avoid immediate retry of same server when others are available to try.
- Added connection stats.
- Added save_query_callback for custom debug logging.
- Refined SRTM granularity. Now only send reads to masters when the written table is involved.
- Improved connection reuse logic and added mysql_ping to recover from «server has gone away».
- Added min_tries to configure the minimum number of connection attempts before bailing.
- Added WPDB_PATH constant. Define this if you’d rather not use ABSPATH . WPINC . ‘/wp-db.php’.